Modern Data Stack: Chrono24’s Weg in die Cloud
Der Weg zu einer skalierbaren Cloud-Lösung: Herausforderungen, Entscheidungen und die Integration von Machine Learning.
Autoren: Christian Freischlag, Fabio Krämer und Sebastian Tritsch

Bei Chrono24 arbeiten wir datengetrieben. Die Bereitstellung der Daten innerhalb unserer Analytics-Architektur erfolgte lange über eine MySQL-Datenbank in Kombination mit einer BI-Lösung, die mittels eines klassischen ETL-Prozesses beladen wurde. Doch diese Analytics-Architektur stieß mit dem Wachstum des führenden Marktplatzes für Luxusuhren an seine Grenzen.
Nachdem wir nun die Migration auf eine Cloud-Datenplattform abgeschlossen haben und einige Jahre auf den Betrieb zurückblicken können, möchten wir in diesem Artikel beleuchten, welche Fragestellungen uns zu unserem Cloud-basierten Data-Stack geführt haben, mit welchen Problemen wir dabei kämpfen mussten und wie wir Machine Learning in diesem integriert haben.
Die falsche Technologie für den richtigen Zweck
Bis zum Jahr 2020 haben wir versucht, den Technologiestack des Marktplatzes für unsere Analytics-Architektur zu verwenden. Das bedeutet, dass wir für die Datenbereitstellung auf ein eigens entwickeltes Framework gesetzt haben, welches auf einer verteilten MySQL-Datenbank mit lokalen Caches basiert. Auch die Aufbereitung der Daten wurde nicht über speziell dafür gemachte Technologien ermöglicht, sondern mit Hilfe dieses Frameworks und dazugehöriger Java-Prozesse umgesetzt. Hierbei wurden die Daten aus der Datenbank des Marktplatzes extrahiert, mittels eines Java-Prozesses transformiert und dann in die Datenbank innerhalb der Analytics-Architektur geladen. Erweitert wurde dies durch den umfänglichen Einsatz einer BI-Lösung. Die BI-Lösung wurde hierbei sowohl für die Integration von Quellsystemen und Bereitstellung von Daten in einem proprietären Speicherformat als auch für die Präsentation von Daten in Dashboards verwendet.
Dies hatte zu dieser Zeit logische Gründe: Einerseits gab es noch kein Data Team, welches sich dezidiert um den Betrieb und die Architektur einer Analytics-Plattform gekümmert hat und darüber hinaus bestanden keine Entwicklungskapazitäten abseits des Java-Technologiestacks.
Jedoch wurden die Anforderungen zunehmend größer und so führte dieser Technologiestack zu Problemen, die perspektivisch absehbar durch die Technologieauswahl verursacht waren. Prozesse waren fehleranfällig, nicht modular und unzweckmäßig. Das bedeutete viel Wartungsaufwand und große Latenz zwischen BI-System und Marktplatz. Zudem ist die MySQL-Datenbank eine OLTP-Datenbank und daher nur begrenzt geeignet für OLAP-Anfragen. Die BI-Lösung mit ihrem proprietären Speicherformat stellte sich als Sackgasse heraus. Diese Lösung bot keine Möglichkeit, die Daten wieder vernünftig für weitere Anwendungsfälle zu extrahieren (Reverse ETL). Auch unsere Machine-Learning-basierten Features waren immer etwas komplizierter zu integrieren, da dort auf andere Programmiersprachen gesetzt wurde.
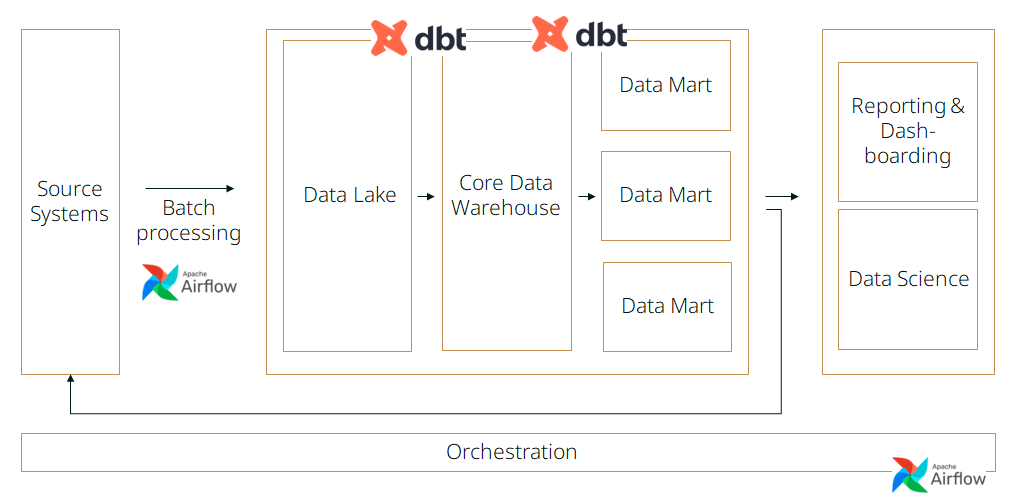
Cloud-Datenplattform
Glücklicherweise erkannten wir frühzeitig, dass Handlungsbedarf besteht – und so starteten wir damit, eine Architektur für eine moderne Datenplattform zu entwickeln. Mit der Validierung von externen Beratern konnten wir anfangs neue Impulse einholen und grobe Fehler vermeiden.
Die Architektur sollte zukunftsfähig und skalierbar sein, aber nicht den Fehler wiederholen, welchen zuvor viele Unternehmen mit „Big Data“-Plattformen gemacht haben – nämlich ohne wirkliche Use Cases für Big Data Analytics Hadoop Cluster mit großem Wartungsaufwand aufzubauen (FOMO), nur um dann festzustellen, dass ihre Anforderungen eigentlich gar nicht dazu passten.
Der Kern unserer Datenplattform sollte in der Cloud liegen, damit wir skalieren können und die Wartungskosten überschaubar sind. Unsere bestehende BI-Lösung sowie Google Analytics und auch unsere bestehenden R– und Python-basierten Data-Science-Projekte sollten einfach zu migrieren sein.
Der größte Aufwand bestand darin, den Java-basierten ETL-Prozess auf eine moderne Technologie zu migrieren. Hierbei war es wichtig, dass wir anbieterunabhängig sind und möglichst auf eine versionierbare Lösung setzen können, die nah am Code liegt und uns viel Kontrolle gibt. Wir wollten von einem ETL-Prozess hin zu einem ELT-Prozess wechseln. Dadurch haben wir uns mehr Flexibilität versprochen.
Außerdem wollten wir die Frequenz der Synchronisierung von Daten des Marktplatzes über CDC flexibel gestalten, damit wir die Kosten selbst in der Hand haben und möglichst viel Kontrolle über die Daten behalten.
Databricks, Snowflake oder BigQuery
Sicherlich eine der wichtigsten Entscheidungen war die Auswahl des Cloud-Data-Warehouses. Hierfür haben wir uns drei Anbieter im Detail angeschaut:
Databricks bietet mit einer Data Lakehouse Lösung eine stark an Big Data Processing angelehnte Infrastruktur. Mit Apache Spark als Processing-Engine können auch ohne viel Integrationsaufwand Streaming und ML Use Cases abgedeckt werden. Besonders stark sticht Databricks bei komplexen Verarbeitungsprozessen hervor. Dies ist allerdings gleichzeitig ein Nachteil, denn die Integration ist ebenfalls komplex und eignet sich auch eher für sehr große Unternehmen.
Snowflake als Data Cloud zeichnet sich durch eine etwas geschlossenere Struktur aus, ist dafür jedoch einfacher in der Anwendung. Zwar bietet Snowflake keine Apache Spark Anbindung out-of-the-box, dafür aber viele Konnektoren, eine einfache UI und Integration über ODBC/JDBC. Snowflake entwickelt sich rasant weiter und kann mit vielen sinnvollen Features überzeugen. Insbesondere wenn der Umstieg von SQL-basierten ETL-Prozessen ansteht und noch kein Spark verwendet wird, ist mit Snowflake eine Migration letztlich nur ein Austausch der Datenbank. Aber auch für Streaming und große Datenmengen bietet Snowflake mit Snowpark eine Spark-Alternative. Neben der proprietären Spark Alternative werden als Nachteil häufig die Kosten genannt.
Googles Big Query ist als managed Data Warehouse ebenfalls einfach zu verwenden und kommt mit einer guten Integration von Google Analytics Daten einher, leidet aber unter inperformanten Queries und generell limitierten Features. Sowohl der etwas eigene SQL-Dialekt als auch die fehlenden Integrationsmöglichkeiten sind nachteilig.
Alle drei bieten Rechteverwaltung und setzen typische Compliance-Anforderungen um. Bei der Entscheidung für eines der Systeme sollten die spezifischen Anforderungen und die bestehende Infrastruktur des Unternehmens berücksichtigt werden. Während Databricks für komplexe, datenintensive Anwendungen geeignet ist, bietet Snowflake eine benutzerfreundlichere und flexiblere Lösung für Unternehmen, die einfache Migrationen und eine breite Palette von Anwendungen priorisieren. BigQuery hingegen ist ideal für Unternehmen, die tief in das Google-Ökosystem integriert sind und eine nahtlose Integration mit anderen Google-Diensten wünschen, obwohl sie möglicherweise Kompromisse bei der Performance und Flexibilität eingehen müssen. Letztendlich hängt die Wahl des richtigen Data Warehouses von den individuellen Bedürfnissen und Zielen ab.
Data Ingestion – kann das so schwer sein?
Es gibt eine Vielzahl von Tools und Frameworks für die Data Ingestion, also den Prozess des Extrahierens und Ladens von Daten. Der Einsatz solcher ist ratsam, da sie das Hinzufügen weiterer Datenquellen erleichtern und viel manuellen Aufwand einsparen können.
Die Auswahl des passenden Tools hat deutlich mehr Zeit in Anspruch genommen als zunächst angenommen. Unser Hauptanwendungsfall war dabei recht klar und unkompliziert: Es galt, Daten aus einer OLTP-Datenbank in unsere Datenplattform zu überführen, wobei auch die Integration weiterer Datenquellen reibungslos möglich sein sollte.
Zuerst haben wir versucht Open-Source-Technologien einzusetzen. Dazu gehörten Airbyte und Meltano. Beide waren zwar einfach aufgesetzt, aber die Probleme waren gewaltig. Nicht nur war die Performance weit unter unseren Ansprüchen, auch die Stabilität ließ zu wünschen übrig. Ein erfolgreicher Sync mit CDC von einer Quelltabelle über mehrere GB war praktisch nicht möglich. Nach einiger Recherche stellte sich heraus, dass weder der verwendete Singer Spec von Meltano für die Workloads geeignet ist (erst Ende 2022 wurde hier nachgebessert) noch Airbyte auf einem soliden Grundgerüst steht.
AWS DMS war hier schon wesentlich erfolgreicher. Das initiale Synchronisieren lief bedeutend schneller (Faktor >10x) und die Replikation war zuverlässig. Leider hätte AWS DMS deutlich mehr manuellen Aufwand bedeutet, um beispielsweise mit Schemaänderungen umzugehen, sodass wir uns weitere Lösungen angeschaut haben, die über das Kernfeature der Replikation hinausgehen. Fivetran und Matillion haben wir uns im Detail angeschaut.
Fivetran und Matillion, beide betrachtet als Lösungen für die Datenintegration, unterscheiden sich in ihren Kernfunktionen und Anwendungsfällen. Fivetran zeichnet sich durch seine einfache Einrichtung und automatisierte Datenpipeline-Prozesse aus, die wenig manuellen Eingriff erfordern und besonders effizient in der Handhabung von Schemaänderungen sind. Diese Vorteile sind jedoch mit höheren Kosten verbunden. Zudem stellen manche Konnektoren bei Fivetran eine Herausforderung dar und erfordern erhebliche Eigenleistung.
Im Gegensatz dazu bietet Matillion, obwohl es mehr manuellen Aufwand erfordert, eine höhere Flexibilität und tiefere Kontrolle für komplexe Datenprozesse. Während Fivetran sich also durch Benutzerfreundlichkeit und Anpassungsfähigkeit auszeichnet, punktet Matillion mit seiner Flexibilität und maßgeschneiderten Transformationsmöglichkeiten, was es für anspruchsvollere Datenverarbeitungsaufgaben geeigneter macht. Beide Tools haben ihre eigenen Stärken und Schwächen und die Wahl hängt letztlich von den spezifischen Anforderungen und Ressourcen ab.
Datentransformation – deklarativ vs. imperativ
Wie schon erwähnt wollten wir einen ELT-Prozess, der code-basiert und möglichst deklarativ ist. Die Erfahrungen mit dem fehleranfälligen imperativen Java waren mit ein Grund für DBT und gegen Spark. DBT ist ein CLI-Tool, welches es ermöglicht Transformationen aufeinander aufbauend zu gestalten (DAG), ohne dabei in unübersichtliches SQL zu münden. DBT ist außerdem „nur“ eine Template-Engine für SQL – d. h. alles, was DBT generiert, bleibt valides SQL und unterstützt damit genau die Features, die Snowflake als Processing-Backend bietet. Die Datenverarbeitung findet also in der Cloud statt, ähnlich wie bei Spark auch.
Darüber hinaus bietet DBT nicht nur die Möglichkeit, Tests zu definieren, sondern auch der Erweiterung durch Macros sowie der Dokumentation mit Data Linage. Hierdurch kann jeder Anwender nachvollziehen, wie die Daten aus den Rohdaten erzeugt werden.
Ein Nachteil von DBT ist sicherlich die eingeschränkte Komplexität der Berechnungen, die über SQL abgebildet werden können. Zwar versucht Snowflake durch das Bereitstellen von UDFs (User Defined Functions) und spezialisierten SQL-Funktionen eigene Abhilfe zu schaffen, aber die Mächtigkeit von imperativen Programmen ist hier doch größer. Allerdings können über Python Models auch diese integriert werden.
Orchestrierung
Die letzte größere Entscheidung hinsichtlich der Datenplattform war die Wahl des Orchestrierungstools. Hier gab es zu dem Zeitpunkt Airflow 2, Prefect, Dagster und Luigi als Open-Source-Lösungen zur Auswahl.
Da Dagster damals noch in der Beta-Phase war, flog es schnell aus dem Rennen, wäre heute aber eventuell eine echte Alternative. Luigi fehlten einige Features und war deshalb auch nicht mehr in der engeren Auswahl.
Ursprünglich war Prefect unsere bevorzugte Wahl, stieß jedoch auf ein entscheidendes Hindernis – es fehlte ein SSH-Operator. Damit der Prefect Scheduler Taks verteilen kann, war es notwendig, dass ein Agent auf jedem Zielsystem installiert war. Dies ist allerdings für Produktivsysteme sicherheitskritisch, weshalb Prefect nicht mehr in Betracht kam. Airflow hingegen zeigte sich als leistungsstarkes Instrument, das nach einer kurzen Eingewöhnungsphase trotz seiner etwas veralteten Benutzeroberfläche effektiv genutzt werden konnte und eine riesige Community hat.
Machine-Learning-Integration
Beim Aufbau unserer Machine-Learning-Plattform war der Begriff MLOps noch nicht weit verbreitet. Zwar existierten bereits Werkzeuge wie MLFlow, jedoch erwiesen sich die vollmundigen Versprechungen bezüglich ML-Plattformen schnell als überzogen – sie waren unflexibel, kostspielig und boten keine GPU-Unterstützung und einfache Integration. Daher entschieden wir uns, eine eigene Tool-Landschaft auf Basis von Open-Source Lösungen zu entwickeln.
Für einen Großteil unserer R– und Python-Projekte nutzen wir Docker Container, die isoliert voneinander ausgeführt werden und Daten direkt in R/Python im Container verarbeiten. Diese Projekte werden in Git-Repositories versioniert und mittels CI-Pipelines in Container für verschiedene Einsatzbereiche wie Entwicklung und Produktion gebaut. Airflow-Jobs steuern die Ausführung dieser Container, welche benötigte Daten aus Snowflake laden, und Ergebnisse zurückschreiben. Mittels terraform können wir außerdem auch Cloud-Dienste nutzen.
Durch die Orchestrierung in Airflow, statt zeitlich gesteuerter Tasks über crontab, werden Latenzzeiten verringert und Abhängigkeiten vollständig transparent. Die Mehrheit unserer produktiven Data-Science-Projekte folgt demnach typischen Batch-Verarbeitungsprozessen und schreibt die Ergebnisse anschließend über reverse-ETL in unsere Systeme zurück. Für das Monitoring setzen wir auf den ELK Stack und außerdem neptune.ai für die das ML-spezifische Experiment-Tracking.
Diese ML-Plattform bietet uns hohe Flexibilität, große Unabhängigkeit und geringe Kosten bei moderatem Wartungsaufwand.
Für komplexere Quasi-Echtzeit-Anwendungen werden eigene Architekturen entworfen, die genau auf den spezifischen Use-Case ausgerichtet sind. Für diese deployen wir unsere Modelle über die Cloud und stellen APIs bereit. Darüber hinaus werden auch moderne Vektor-Datenbanken wie z. B. Milvus eingesetzt. Solche Embedding-basierte Systeme (Recommendations, Watch Scanner) sind typischerweise so individuell, dass eine Standardisierung wenig Sinn ergibt.
Ein lohnendes Ergebnis
Zusammenfassend lässt sich sagen, dass sich die Entscheidung hin zur Cloud-Datenplattform definitiv gelohnt hat. Durch die moderne Infrastruktur können Anforderungen schneller umgesetzt werden und die Stabilität sowie Aktualität der Daten ist deutlich erhöht. Weiterhin war die Integration unserer ML-Integration reibungslos möglich. Der gesamte Prozess war geprägt von sorgfältiger Planung, Tests und kontinuierlichem Lernen – und wir hoffen, dass unsere Erfahrungen auch für andere wertvolle Einblicke geben konnten.