A/B/n testing the world’s luxury watch market

A/B/n-Testing ist für digitale Unternehmen ein wichtiges Werkzeug, um Entscheidungsgrundlagen zu schaffen. Änderung an einer Website oder einer App können besser bewertet werden – bei Fragen oder Unsicherheiten, kann ein A/B/n-Test Klarheit verschaffen.
Das ist auch bei Chrono24 so: Da wir datengetrieben arbeiten, nutzen wir A/B/n-Testing schon seit einigen Jahren, um unsere Plattform und die Apps fortlaufend zu optimieren und besser auf die Bedürfnisse der Nutzer abzustimmen. Um unserem eigenen hohen Anspruch gerecht zu werden, verwenden wir die besten Tools und arbeiten stets daran, das A/B/n-Testing bei Chrono24 zu optimieren.
Der Verkauf von Luxusuhren funktioniert allerdings anders als beispielsweise der Verkauf von Kleidung: Der Kaufprozess dauert deutlich länger aufgrund der höheren Preise und auch der Anspruch der Kunden ist noch höher als bei anderen Warengruppen. Es kommt daher seltener zu einem Kauf als bei einer Hose, wodurch weniger Conversions entstehen, was zu Problemen bei der Auswertung von A/B/n-Tests führen kann.
In diesem Blog-Beitrag möchte ich einen Einblick in das A/B/n-Testing im Luxusuhren-Segment geben und auf die Herausforderung von wenigen Conversions eingehen. Natürlich sind auch die Standard-Anforderungen eines A/B/n-Tests in unseren Prozessen fest verankert: Vorige Laufzeitberechnung und Definition einer Testhypothese, Testlaufzeit nicht unterhalb einer Woche, usw. Auf diese Standardanforderungen werde ich in dem Beitrag allerdings nicht weiter eingehen.
Der Start mit den besten Tools am Markt und erste Testing-Erfolge
Der Startschuss für A/B/n-Testing hat bei uns vor einigen Jahren begonnen. Wir haben bereits zu Beginn mit den besten Tools gearbeitet, „State of the Art“-A/B/n-Testing betrieben und erste sehr positive Testingerfolge verzeichnen können. Da wir stets dabei sind unsere Arbeit zu hinterfragen und zu verbessern, haben wir uns die kritische Frage gestellt, ob wir richtig testen oder ob wir noch mehr auf die Besonderheiten des Luxusuhren-Segmentes eingehen müssen. Dazu kam das Misstrauen in eine Blackbox und der Wille, A/B/n-Testing noch weiter zu optimieren.
Um das herauszufinden, die besten Methoden zu definieren und das Testing weiter zu professionalisieren, haben wir einen Workshop mit Mathematikern durchgeführt und alle Prozesse kritisch hinterfragt. Das Ergebnis aus diesem Workshop war, dass die eingesetzten Tools sehr gut funktionieren und unsere Testergebnisse auch korrekt und valide waren, auch wenn man nicht genau weiß, wie die Berechnung funktioniert. Dabei wollten wir es allerdings nicht belassen. Ein anderes Ergebnis des Workshops war es deshalb, eine eigene Testing- und Auswertungs-Lösung zu erstellen. Außerdem haben wir beschlossen das Signifikanz-Niveau auf 98% zu erhöhen, um noch mehr Sicherheit in die Testergebnisse zu bringen und so unserem Anspruch gerecht zu werden.
Ein weiteres Optimierungspotential haben wir in der Verbesserung des sogenannten Flickering-Effektes gesehen. Der Effekt bezeichnet das Flackern der Seite, der entsteht bevor die Testvariante geladen ist: zuerst wird die Original-Seite oder Control-Variante geladen, die Seite flackert kurz und dann wird erst die Testversion sichtbar. Dies kann den Nutzer und somit auch das Testergebnis beeinflussen, wenn zum Beispiel etwas auf der Seite in dem Test ausgeblendet wird, und der Nutzer es dadurch trotzdem kurz sieht. Dieser sehr ungünstige Effekt tritt bei allen Tools, mit denen wir gearbeitet haben, in unterschiedlichen Ausprägungen auf. Der Effekt wird verstärkt durch das asynchrone Laden der Tools, was aber aus unserer Sicht notwendig ist, um eine sichere Abwicklung des Tests zu gewährleisten (Erreichbarkeit des Tools, Ladezeit, usw.).
Ein weiterer Punkt, den wir ändern wollten, war, dass häufig die Auswertung der Tests bei einer geringen Anzahl an Conversions schwierig und somit keine Verknüpfung der Messergebnisse mit Zahlen aus der Datenbank möglich ist.
Trotz der vielen positiven Erfahrungen mit den verwendeten Tools haben wir uns aus den angesprochenen Gründen dazu entschieden, eine eigene Lösung für A/B/n-Tests zu entwickeln.
Ein eigenes Tool zur Auswertung von Testergebnissen
Durch die Entscheidung für A/B/n Testing eine eigene Lösung zu entwickeln, wurde der Grundstein für unser Tool „KINTT“ gelegt: das Kontrolliert INtegrierte Testing Tool.
Das Erste, dass wir mit dem KINTT noch besser machen wollten, war die Auswertung von Testergebnissen: Wichtig war für uns, wie bereits beschrieben, trotz weniger Conversions unsere Tests statistisch so verlässlich wie möglich auswerten zu können.
Dazu haben wir zuerst begonnen, unsere A/B/n-Tests in unserer Datenbank zu erfassen. Dadurch können wir wesentlich mehr geschäftsrelevante Kennzahlen miteinander vergleichen und auswerten. Außerdem haben wir darauf geachtet, dass wir für die Bewertung der Signifikanz von Unterschieden ausgewählter Metriken ein statistisches Verfahren einsetzen, dass auch bei geringen Datenmengen sehr schnell trennscharfe Ergebnisse liefert.
Die daraus entstandene Berechnungsmethodik wurde dann durch eine auf das Wesentliche reduzierte, aber nutzerfreundliche Oberfläche ergänzt.
Gefüttert wird das so entstandene KINTT mit Datensätzen für die verschiedenen Testgruppen. Es ermittelt dann, ob sich die Gruppen in den angegebenen Metriken unterscheiden. Auch starke Tendenzen können abgebildet werden, selbst bei wenigen Conversions. Das Tool löst auch das Problem, dass ein Ergebnis schnell verzerrt wird, wenn bspw. ein Test auf Basis von Preisen bewertet wird und in einer Gruppe ein Ausreißer vorhanden ist. Hier würden marktübliche Tools schnell zu einem falschen Ergebnis gelangen. Die Voraussetzung für verlässliche Ergebnisse ist selbstverständlich weiterhin, dass die Testgruppen, die verschiedene Varianten eines Produktes angeboten bekommen haben, zufällig zugeordnet worden sind. Ein typisches Experiment bzw. A/B/n-Test also.
Der Output aus dem KINTT sieht dann wie folgt aus:
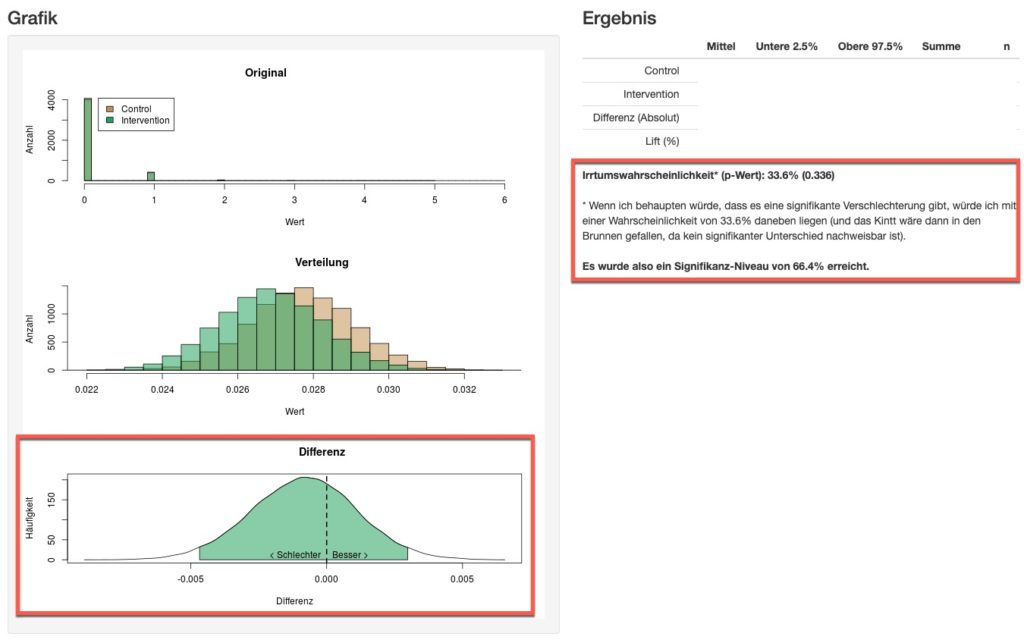
Die Einteilung in Testgruppen
Das Zweite, das wir durch ein eigenes A/B/n-Testing Tool optimieren wollten, war der Flickering-Effekt. Um das zu erreichen, haben wir uns dazu entschlossen, die Einteilung in Testgruppen bereits beim Laden der Seite, auf der der Test stattfindet, durchzuführen, und zwar mit einer eigenen zufälligen Verteilung. Dadurch funktioniert die Einteilung in Gruppen wesentlich schneller. Dies ermöglicht es, die Testvariante anzuzeigen, während die Seite vollständig lädt und es entsteht für den Nutzer kein Flickern, wodurch er eventuell beeinflusst werden könnte. Andere Tools haben den Flickering-Effekt zwar auch fast vollständig eliminiert, dank unserer Lösung entsteht er allerdings gar nicht mehr.
Eine Nutzeroberfläche für das KINTT
Nach der Einteilung in Testgruppen mussten wir es nur noch ermöglichen, Testvarianten auf eine einfache und effektive Art erzeugen zu können. Wir haben es geschafft, Tests in der Umsetzung durch einen einfachen Parameter so zu definieren, dass unsere Entwickler Testvarianten erstellen können, die so einfach wie normale Änderungen an einer Seite umgesetzt werden.
Damit aus der neuen Testing-Lösung auch eine nutzerfreundliche Lösung wird, haben wir für das Management von Testvarianten eine übersichtliche Oberfläche programmiert. Tests können damit ganz einfach in der Benutzeroberfläche angelegt werden. Außerdem kann das KINTT mit Bots, Devices und parallelen Tests umgehen.
Fazit
Nachdem wir bereits marktübliche A/B/n-Testing Tools verwendet und einige erfolgreiche Tests durchgeführt hatten, sind wir zu dem Entschluss gekommen, dass das Testing im Luxusuhren-Segment mit einem eigenen Tool, das unseren hohen Ansprüchen gerecht wird, noch viel besser funktionieren kann.
Durch das so entstandene KINTT sind wir sehr flexibel und können Tests besser steuern und auswerten. Ein weiterer positiver Nebeneffekt – bis auf den Invest der Entwicklungskosten entstehen mit dieser Lösung keine weiteren Folgekosten des A/B/n-Testings. Die Entwicklungskosten konnten ebenfalls auf ein Minimum beschränkt werden.
Auch wenn wir das KINTT für die meisten unserer A/B/n-Tests einsetzen, haben wir weiterhin ein externes Tool im Einsatz, um schnell kleinere Tests durchführen zu können. Bei diesen Tests nutzen wir allerdings auch unsere eigene Berechnungslogik.
Wir haben sogar vergangene Testergebnisse rückwirkend neu berechnet, um festzustellen, dass die Signifikanzen besser sind als vorher mit den externen Anbietern.
Es gibt sicherlich auch einige Nachteile unserer Lösung, wie zum Beispiel, dass die Oberfläche nicht so fortgeschritten und einfach zu bedienen ist wie die eines Tools, das ein Hersteller fortlaufend weiterentwickelt. Für uns hat sich das KINTT aber zu einer sehr guten Lösung entwickelt, die fehlerfrei und in einer für uns gut passenden Art und Weise funktioniert. Wir freuen uns auf viele weitere Tests, aus denen wir weiter lernen können.